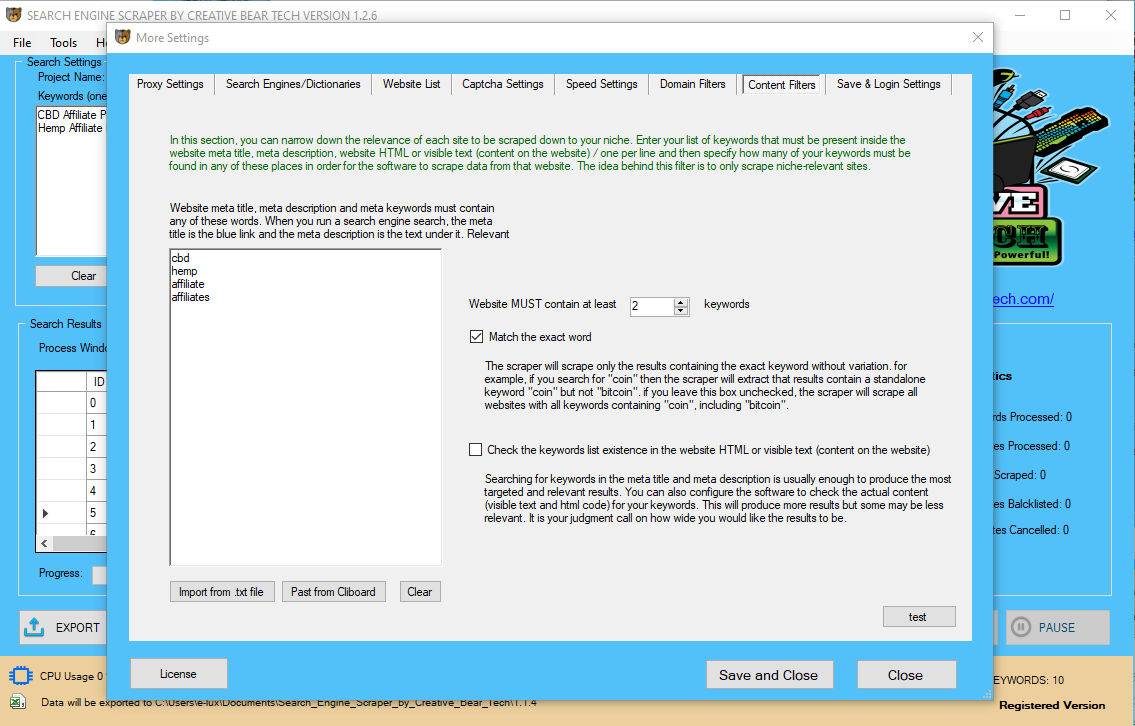
Is There Any Python Lib To Scrape Search Engine
Content
- Search Engine Scraping
- Need To Scrape Google Search Results? Get Your Top-a hundred Results For Any Keyword!
- Skill & Expertise Of Deep Crawling & Intelligent Extraction Of Data From Different Search Engines
- Is There Any Python Lib To Scrape Search Engine(s) Results?
- Googlescraper - Scraping Search Engines Professionally
Search Engine Scraping
If you might be having hassle following this guide, please see the video on the very prime of this weblog post where I present step-by-step directions. And as another reminder, the code proven above is anupdateto this weblog post. The YouTube video at the high of this submit is not going to and doesn't match this up to date code, however the handbook JavaScript console intervention is identical. Simply paste each snippet into the console until you've your URLs textual content file. After executing the above snippet you’ll have a file named urls.txtin your default Downloads listing.
Need To Scrape Google Search Results? Get Your Top-one hundred Results For Any Keyword!
 The technique I’m about to share with you for gathering Google Images for deep studying is from a fellow deep studying practitioner and pal of mine, Michael Sollami. And to make matters worse, manually annotating a picture dataset is usually a time consuming, tedious, and even expensive process. I’ve discovered a small dataset (~one hundred images per class), but my models are fast to overfit and far from correct. Now that you have given the choose() methodology in BeautifulSoup a brief take a look at drive, how do you discover out what to produce to select()? The fastest means is to step out of Python and into your web browser’s developer instruments.
The technique I’m about to share with you for gathering Google Images for deep studying is from a fellow deep studying practitioner and pal of mine, Michael Sollami. And to make matters worse, manually annotating a picture dataset is usually a time consuming, tedious, and even expensive process. I’ve discovered a small dataset (~one hundred images per class), but my models are fast to overfit and far from correct. Now that you have given the choose() methodology in BeautifulSoup a brief take a look at drive, how do you discover out what to produce to select()? The fastest means is to step out of Python and into your web browser’s developer instruments.
Skill & Expertise Of Deep Crawling & Intelligent Extraction Of Data From Different Search Engines
So, we inspect the page to see, underneath which tag the data we need to scrape is nested. To examine the page, excellent click on on the element and click on “Inspect”. In this article onWeb Scraping with Python, you will find out about net scraping in short and see tips on how to extract data from an internet site with an illustration. I was struggling to scrape knowledge from search engines, and the “USER_AGENT” did helped me. You have to scale back the rate at which you might be scraping Google and sleep between every request you make.
Is There Any Python Lib To Scrape Search Engine(s) Results?
You can use your browser to look at the doc in some detail. I often search for id or class element attributes or any other information that uniquely identifies the information I want to extract. The example code within the article was modified to no longer make requests to the XTools website. The net scraping methods demonstrated listed below are nonetheless legitimate, however please don't use them on web pages of the XTools project. Write a program that, given the URL of an online web page, will try and download each linked page on the page.
Googlescraper 0.2.four
Our major entry level to start out execution is this call to grabUrls. Notice how every URL is joined by a newline character so that each URL is by itself line within the text file.
Vitamins and Supplements Manufacturer, Wholesaler and Retailer B2B Marketing Datahttps://t.co/gfsBZQIQbX
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
This B2B database contains business contact details of practically all vitamins and food supplements manufacturers, wholesalers and retailers in the world. pic.twitter.com/FB3af8n0jy
Skip the hassle of putting in software, programming and maintaining the code. Point and click internet scraping instruments have a visible interface, where Facebook Email Scraper you can annotate the info you want, and it automatically builds an internet scraper with these instructions.
This is because it's difficult to prove copyright over such knowledge since only a specific association or a particular number of the data is legally protected. A Web scraper is built specifically to handle the construction of a selected website. The scraper then makes use of this site-particular structure to extract particular person knowledge elements from the website. A internet scraper is a software program or script that is used to obtain the contents (often textual content-based and formatted as HTML) of multiple web pages and then extract knowledge from it. One potential cause might be that search engines like google like Google are getting virtually all their data by scraping hundreds of thousands of public reachable websites, additionally with out reading and accepting these phrases. A authorized case won by Google in opposition to Microsoft would possibly put their complete enterprise as danger. The largest public identified incident of a search engine being scraped happened in 2011 when Microsoft was caught scraping unknown key phrases from Google for their very own, somewhat new Bing service. The program should flag any pages which have a 404 “Not Found” standing code and print them out as damaged hyperlinks. Most boring tasks aren’t restricted to the information on your computer. While web scraping may be done manually by a software program person, the term sometimes refers to automated processes implemented utilizing a bot or internet crawler. It is a type of copying, by which particular knowledge is gathered and copied from the online, usually right into a central local database or spreadsheet, for later retrieval or analysis. Hey Vik — usually we use object detection instead of image classification to detect and localize logos. This is typically because many logos are only part of the context of the overall picture. Using the requests library, we make a get request to the URL in question. We additionally move in a User-Agent to the request to keep away from being blocked by Google for making automated requests. Without passing a User-Agent to a request, you might be prone to be blocked after only some requests. It shouldn't be a problem to scrape 10'000 key phrases in 2 hours. Being capable of programmatically obtain internet pages will lengthen your applications to the Internet. The requests module makes downloading easy, and with some fundamental knowledge of HTML ideas and selectors, you can utilize the BeautifulSoup module to parse the pages you obtain. If you’re simply making an attempt to get the ropes of image classification I wouldn’t begin with logo detection and recognition, it’s just too difficult. If you want to proceed although, you’ll need to annotate your photographs to have the bounding field coordinates of the logos for object detection. This is a particular form of display scraping or internet scraping dedicated to search engines like google solely. Get important search engine optimization related data from Search Engines & different web sites by creating Custom Search Engine Scrapers or by getting regular Web Data Services as per requirement. Web scraping, also referred to as web information mining or net harvesting, is the method of setting up an agent which may extract, parse, obtain and arrange helpful data from the net automatically. This submit describes how you can programmatically search the PubMed database with Python, so as to combine looking out or searching capabilities into your Python application. This Edureka stay session on “WebScraping using Python” will assist you to perceive the fundamentals of scraping along with a demo to scrape some details from Flipkart. When then initialise our outcomes variable, which is going to be a list of dictionary components. By making the results a list of dictionary parts we make it very straightforward to use the info in variety of different Search Engine Harvester ways. Parsing the HTML, will enable us to extract the weather we would like from the Google results web page. For this we are utilizing BeautifulSoup, this library makes it very easily to extract the data we would like from a webpage.
- In this blog publish we realized tips on how to use Python scrape all cowl images ofTime journal.
- Overall, our entire spider file consisted of less than44 traces of code which actually demonstrates the power and abstraction behind the Scrapy libray.
- To accomplish this task, we utilized Scrapy, a quick and highly effective internet scraping framework.
- Using requests, we just have to specify the urland a timeout for the download.
There isn't any more need to scrape immediately on the HTTP protocol stage. It's too bugy and too straightforward to fend of by anit-bot mechanisms. Poking round, the consensus appears to be that downloading the images for the purpose of coaching a network is covered under ‘honest use’. The images can't be reconstructed from the educated network. If I were to redistribute the photographs then it would be a different story. Than localize them (on 98% of photographs dogs coordinates have been discovered appropriately), crop them and save. For what it’s price, I cover deep studying-primarily based object detection in detail inside my e-book, Deep Learning for Computer Vision with Python. In the long run enhancements I plan to make Data augmentation attainable like you counsel in your second article. And perhaps take image from multiple sources, not only Google to have fallback options. Common reasons for a picture being unable to load embody an error during the download (corresponding to a file not downloading completely), a corrupt image, or a picture file format that OpenCV can not read. And finally, we replace our total depend of downloaded images. From there, we load every URL from the file into an inventory onLine 18. Ruby on Rails in addition to Python are additionally incessantly used to automated scraping jobs. For highest performance C++ DOM parsers ought to be thought-about. Behaviour based mostly detection is the most difficult defense system. Search engines serve their pages to hundreds of thousands of users every single day, this provides a large amount of behaviour info. If you're really loopy, set the maximal browsers in the config somewhat bit higher (in the prime of the script file). Because GoogleScraper helps many search engines and the HTML and Javascript of those Search Providers adjustments regularly, it's typically the case that GoogleScraper ceases to operate for some search engine. It supports a wide range of different search engines like google and is much more efficient than GoogleScraper. The code base can be much much less complicated without threading/queueing and complex logging capabilities. Scraping in 2019 is almost fully reduced to controlling webbrowsers. As you'll be able to see, the createDownload function is known as from here as the final step. This operate successfully simulates proper clicking on an image proven in your browser. Notice how the click involves dispatching both a mousedown and mouseup occasion followed by activating the context menu. The requests module merely handles downloading the contents of internet pages. Once the page is downloaded, it's simply data in your program. Even if you had been to lose your Internet connection after downloading the web page, all of the web page information would still be in your pc. The requests module was written because Python’s urllib2 module is just too complicated to make use of.  howdy sir, I must say that you just blogs are finest.Sir there's a extension named FATKUN which might obtain all the images on the page. This is definitely a brilliant extension, after having tried variety of scripts, a chrome extension and failed I came to find this one. Within minutes of copying the script from their example I was able to obtain pictures of higher decision that I wanted. One concern I had was about infringing copyright by utilizing the pictures. It can detect unusual activity much quicker than different search engines like google. Search engine scraping is the method of harvesting URLs, descriptions, or other information from search engines like google corresponding to Google, Bing or Yahoo. The simplest type of net scraping is manually copying and pasting data from a web page right into a textual content file or spreadsheet. Web scraping, internet harvesting, or internet knowledge extraction is data scraping used for extracting information from web sites. Web scraping software program could entry the World Wide Web instantly utilizing the Hypertext Transfer Protocol, or via a web browser. We can then use this script in a number of completely different situations to scrape results from Google. The fact that our results information is a list of dictionary gadgets, makes it very straightforward to put in writing the information to CSV, or write to the outcomes to a database. There are a variety of totally different errors that could possibly be thrown and we look to catch all of these possible exceptions. The User-Agent helps web sites identify your browser and working system, and provides sites the ability to customize the expertise based on the features of your User-Agent. By default the requests library customers a header which identifies itself as the Python requests library. That makes it very straightforward for web sites to easily block requests using this header. We can modify our headers to make it appear that we're using an actual browser when making requests, but there are nonetheless methods of detecting requests made with a library corresponding to requests, versus with an actual browser. In this tutorial, we are going to talk about Python net scraping and tips on how to scrape web pages using a number of libraries similar to Beautiful Soup, Selenium, and some other magic tools like PhantomJS. Specifically, we’ll be scrapingALLTime.com magazine cover photographs. We’ll then use this dataset of magazine cover photographs in the subsequent few weblog posts as we apply a sequence of image evaluation and laptop vision algorithms to raised explore and perceive the dataset. In the remainder of this blog publish, I’ll show you the way to use the Scrapy framework and the Python programming language to scrape photographs from webpages.
howdy sir, I must say that you just blogs are finest.Sir there's a extension named FATKUN which might obtain all the images on the page. This is definitely a brilliant extension, after having tried variety of scripts, a chrome extension and failed I came to find this one. Within minutes of copying the script from their example I was able to obtain pictures of higher decision that I wanted. One concern I had was about infringing copyright by utilizing the pictures. It can detect unusual activity much quicker than different search engines like google. Search engine scraping is the method of harvesting URLs, descriptions, or other information from search engines like google corresponding to Google, Bing or Yahoo. The simplest type of net scraping is manually copying and pasting data from a web page right into a textual content file or spreadsheet. Web scraping, internet harvesting, or internet knowledge extraction is data scraping used for extracting information from web sites. Web scraping software program could entry the World Wide Web instantly utilizing the Hypertext Transfer Protocol, or via a web browser. We can then use this script in a number of completely different situations to scrape results from Google. The fact that our results information is a list of dictionary gadgets, makes it very straightforward to put in writing the information to CSV, or write to the outcomes to a database. There are a variety of totally different errors that could possibly be thrown and we look to catch all of these possible exceptions. The User-Agent helps web sites identify your browser and working system, and provides sites the ability to customize the expertise based on the features of your User-Agent. By default the requests library customers a header which identifies itself as the Python requests library. That makes it very straightforward for web sites to easily block requests using this header. We can modify our headers to make it appear that we're using an actual browser when making requests, but there are nonetheless methods of detecting requests made with a library corresponding to requests, versus with an actual browser. In this tutorial, we are going to talk about Python net scraping and tips on how to scrape web pages using a number of libraries similar to Beautiful Soup, Selenium, and some other magic tools like PhantomJS. Specifically, we’ll be scrapingALLTime.com magazine cover photographs. We’ll then use this dataset of magazine cover photographs in the subsequent few weblog posts as we apply a sequence of image evaluation and laptop vision algorithms to raised explore and perceive the dataset. In the remainder of this blog publish, I’ll show you the way to use the Scrapy framework and the Python programming language to scrape photographs from webpages.
Global Vape And CBD Industry B2B Email List of Vape and CBD Retailers, Wholesalers and Manufacturershttps://t.co/VUkVWeAldX
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Vape Shop Email List is the secret sauce behind the success of over 500 e-liquid companies and is ideal for email and newsletter marketing. pic.twitter.com/TUCbauGq6c
In fact, take a everlasting marker and black out this whole paragraph. If you should download issues from the Web, just use the requests module. I have an utility that makes use of PHP and Python to run a website scraper. It quit working a few days in the past (after working for over a 12 months) and I want someone who can troubleshoot each applications. In this case, any hidden subject with real worth or worth that is totally different from expected could also be uncared for, and the person may even be banned from the website. But within the cases the place you possibly can’t find a dataset that suits your wants (or if you need to create your personal customized dataset), you might be left with the duty ofscraping and gathering your photographs. While scraping a website for photographs isn’t precisely a computer vision method,it’s still an excellent talent to have in your device belt. Legality is completely depending on the authorized jurisdiction (i.e. Laws are country and locality particular). Publicly available info gathering or scraping just isn't illegal, if it had been unlawful, Google would not exist as an organization as a result of they scrape knowledge from each website in the world. Most occasions an internet scraper is free to copy a bit of knowledge from an online page with none copyright infringement. A scraping script or bot just isn't behaving like an actual user, except for having non-typical access occasions, delays and session instances the key phrases being harvested could be associated to each other or embody unusual parameters. Google for example has a really sophisticated behaviour analyzation system, probably utilizing deep learning software to detect unusual patterns of entry. Firstly, if you pass knowledge for the incorrect kind to the fetch outcomes function, an assertion error might be thrown. Should we get banned we will be introduced with a HTTP Error and may we've some type of connection problem we'll catch this using the generic requests exception. Our parse results operate begins by making a ‘soup’ out of the html we pass to it. This primarily simply creates a DOM object out of a HTML string allowing to select and navigate by way of completely different page parts.
Beauty Products & Cosmetics Shops Email List and B2B Marketing Listhttps://t.co/EvfYHo4yj2
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Beauty Industry Marketing List currently contains in excess of 300,000 business records. pic.twitter.com/X8F4RJOt4M
Or alternatively you can make use of proxies and rotate them between requests. A User-Agent is simply a string which you show when you make HTTP requests. When human’s evaluate is needed, just take a look at cropped thumbnails to be one hundred% sure that one dogs’ specious is nice. We then manually inspected the images and eliminated non-relevant ones, trimming the dataset all the way down to ~460 images. The error you see in the output is normal — you must expect these. You also needs to count on some photographs to be corrupt and unable to open — these photographs get deleted from our dataset. We also initialize a counter, complete, to count the recordsdata we’ve downloaded. Notice requestson Line 4 — this will be the bundle we use for downloading the picture content.
Are you looking for CBD capsules? We have a wide selection of cbd pills made from best USA hemp from discomfort formula, energy formula, multivitamin formula and nighttime formula. Shop Canabidol CBD Oral Capsules from JustCBD CBD Shop. https://t.co/BA4efXMjzU pic.twitter.com/2tVV8OzaO6
— Creative Bear Tech (@CreativeBearTec) May 14, 2020